Read..csv File and Find the Observations and Its Values

Pandas DataFrame: Playing with CSV files
![]()
CSV stands for Comma Separated Values, A pop way of representing and storing tabular, cavalcade oriented data in a persistent storage
Pandas DataFrames is generally used for representing Excel Like Data In-Memory. In all probability, nigh of the time, we're going to load the data from a persistent storage, which could be a DataBase or a CSV file.
In this mail, nosotros're going to encounter how we can load, store and play with CSV files using Pandas DataFrame
Epitomize on Pandas DataFrame
I've already written a detailed post titled Pandas DataFrame : A Lightweight Intro . If y'all're not comfortable with Pandas DataFrame, I'll highly recommend you to have a look at this post before continuing with this one.
In a n u tshell, Pandas DataFrame is nothing but an in-memory representation of excel similar information. For example,
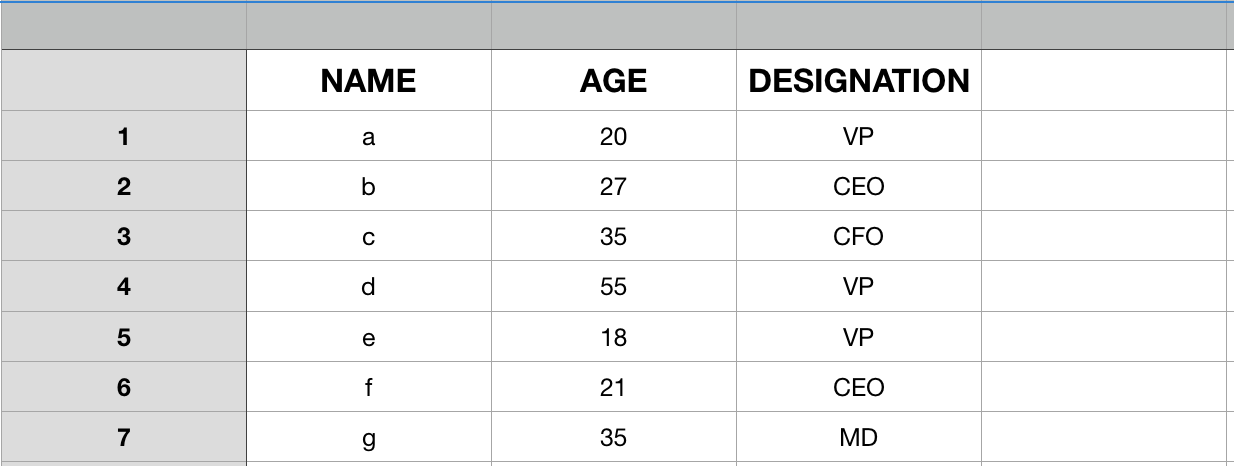
This data tin can also be represented using Python Lexicon as
my_dict = { 'proper noun' : ["a", "b", "c", "d", "e","f", "g"],
'historic period' : [20,27, 35, 55, eighteen, 21, 35],
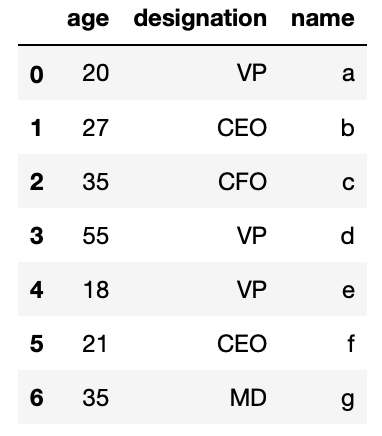
'designation': ["VP", "CEO", "CFO", "VP", "VP", "CEO", "Dr."]} And we know that we tin can create a Pandas DataFrame out of a python dictionary past invoking DataFrame(...) function
df = pd.DataFrame(my_dict) The resultant DataFrame shall look similar
Persisting the DataFrame into a CSV file
One time we accept the DataFrame, we can persist information technology in a CSV file on the local disk. Let's offset create our own CSV file using the information that is currently present in the DataFrame, we tin can shop the data of this DataFrame in CSV format using the API called to_csv(...) of Pandas DataFrame as
df.to_csv('csv_example') Now we have the CSV file which contains the data present in the DataFrame above.
Just equally we tin can persist the DataFrame in a CSV file, we tin can also load the DataFrame from a CSV file.
Let's go alee and load the CSV file and create a new DataFrame out of it
df_csv = pd.read_csv('csv_example') The resultant DataFrame (df_csv) shall wait like
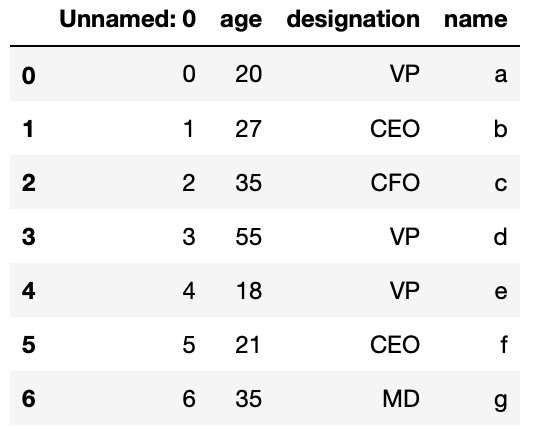
Did you lot notice something unusual?
Well, we tin can see that the index is generated twice, the start 1 is loaded from the CSV file, while the second one, i.e Unnamed is generated automatically by Pandas while loading the CSV file.
This problem can exist avoided past making sure that the writing of CSV files doesn't write indexes, considering DataFrame will generate it anyway. We tin do the aforementioned by specifying index = Faux parameter in to_csv(...) function
df.to_csv('csv_example', index=False) Now, if we read the file as
df_csv = pd.read_csv('csv_example') The resultant DataFrame shall look like
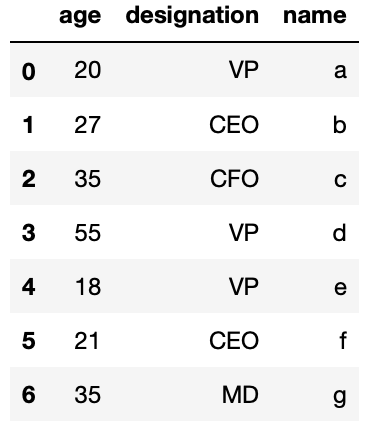
Now you tin see that the output is similar to what we had earlier, when we created the DataFrame from the python dictionary and this is what we're expecting.
Playing with Cavalcade Header
As we've seen that the offset row is always considered every bit column headers, however, it'southward possible to have more than one row as column headers by specifying a parameter called header=<integer> in read_csv(...) office.
By default, the value is specified every bit '0', which ways that the top row will be considered every bit header.
df_csv = pd.read_csv('csv_example', header = 0) The resultant output will be same every bit above. Even so, it open lots of opportunities to play with arranging headers. For example, we tin also have more than one row as header equally
df_csv = pd.read_csv('csv_example', header=[0,one,two]) The resultant DataFrame shall expect like
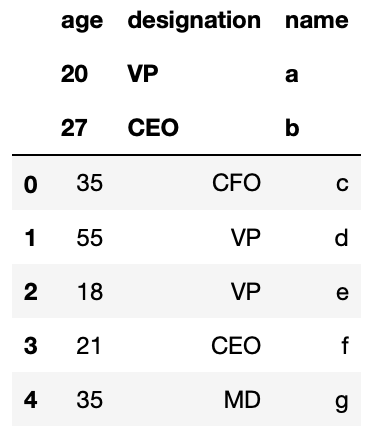
As we encounter over hither that column 0,1, & ii are headers now.
It's also not necessary to have outset sequence of row as a header, we can very well skip beginning few rows then start looking at the table from a specific row
For instance
df_csv = pd.read_csv('csv_example', header=5) Here, the resultant DataFrame shall expect like

The but drawback is that we will have to let go of the information available before the header row number. Information technology tin't be part of the resultant DataFrame.
Even in the example of having multiple rows as header, actual DataFrame data shall start only with rows after the last header rows.
df_csv = pd.read_csv('csv_example', header=[1,2,5]) The resultant DataFrame will first from row 'half-dozen' and shall await like
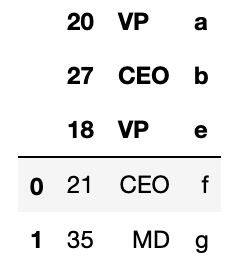
Customizing Column Names
Though we're reading the data from CSV files with Column headers, we can nevertheless have our own column names. We can reach the aforementioned by adding a parameter called names in read_csv(...) as
df_csv = pd.read_csv('csv_example', names=['a', 'b', 'c']) The resultant DataFrame shall look like
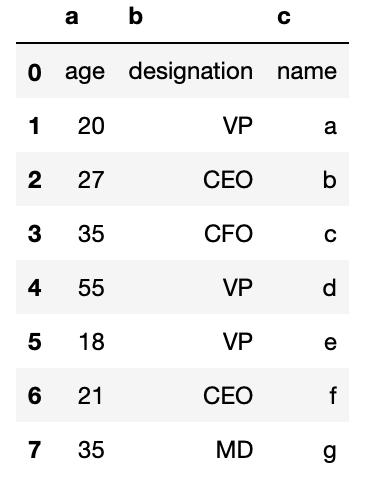
However, even though we are successful in adding our own header, the summit row still displays header which is a not desired ane.
This tin exist avoided by using the header parameter in read_csv(…)to skip the row depicting the header. In this particular case, we know that get-go row, i.east. row 0 is header so nosotros can skip it as
df_csv = pd.read_csv('csv_example', names=['a', 'b', 'c'], header=1) 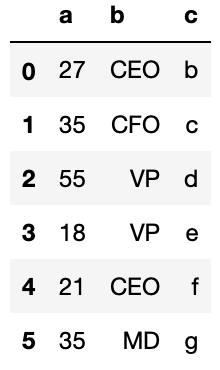
At present, we got the output we were looking for with our customized header.
Another style of doing the same is past skipping the header while writing the CSV files as
df.to_csv('csv_example', index=Faux, header = Imitation) And while reading ,we can read without skipping the header equally
df_csv = pd.read_csv('csv_example', names=['AGE', 'DESIGNATION', 'Proper name']) 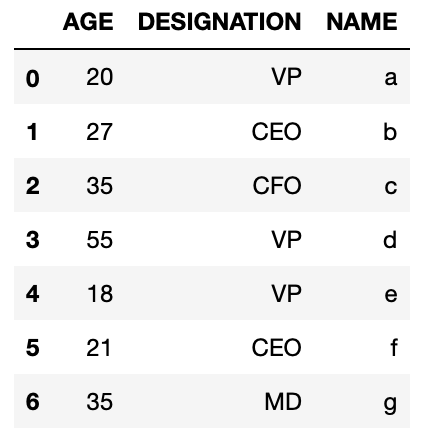
CSV to (Anything) Separated Value
Though comma separated values are well known, the read_csv(...) office can identify separators other than comma.
The only deviation is that we need to pass the separator explicitly in the function while comma is considered by default
Allow'south showtime create a CSV file using a different separator i.e ":" (A colon)
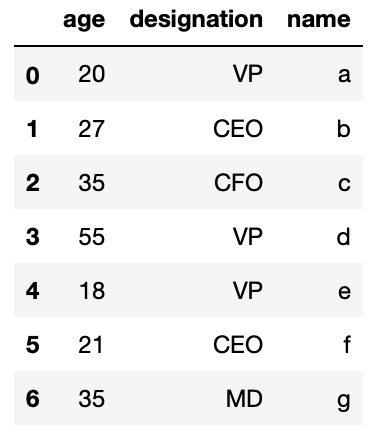
df.to_csv('csv_example', alphabetize=Imitation, sep=":") This volition create a file where the colon (':') instead of comma (',') shall be used equally a separator. We can read the file as
df_csv = pd.read_csv('csv_example', sep=":") The resultant DataFrame shall look like
Setting the Row Alphabetize
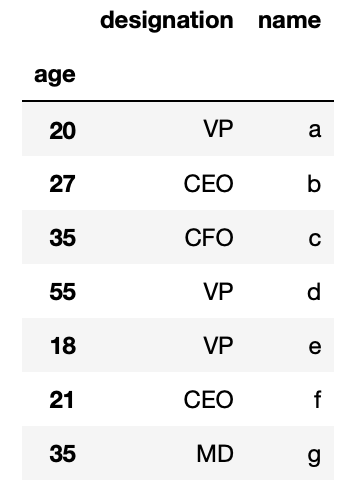
Past default, Pandas DataFrame generates a row index automatically which we can change past setting any column equally the Index every bit
df_csv.set_index('historic period') Here is how the resultant DataFrame shall wait similar
Setting the indexes in this way is a post functioning. i.e we already have a DataFrame with pre defined index, but we change it later.
We can do this at the time of loading CSV file past passing a parameter called index_col , which will automatically assign the column depicted by index_col every bit a row index.
df_csv = pd.read_csv('csv_example', sep=":", index_col=ane) The output of the aforementioned shall look similar

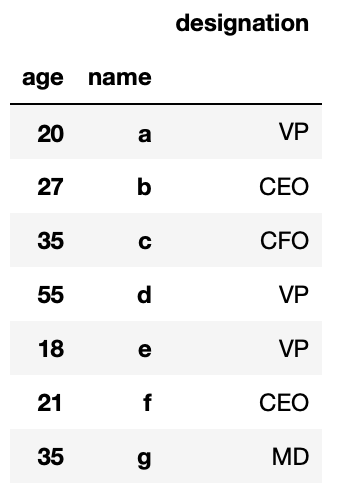
We tin even provide more than than ane index_col to be treated equally index
df_csv = pd.read_csv('csv_example', sep=":", index_col=[0,2]) And the output will wait similar
If all rows are not required… Don't load them
Nearly of the fourth dimension, the CSV files will have considerable size and you might run into retentiveness constraints while loading them. At that place is an selection of loading merely selected few rows from it.
You can do the same by specifying the number of Rows to exist loaded by passing an argument nrows in read_csv(...)
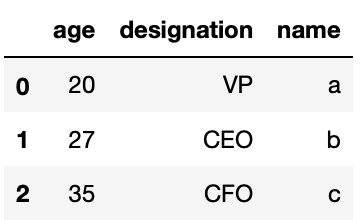
# Load Only 3 Rows
df_csv = pd.read_csv('csv_example', sep=":", nrows=3) And hither is how it will look like
Skipping Empty Lines in CSV files
By default,
read_csv(...)function skips bare line, i.east it will ignore bare lines while loading the file and constructing the DataFrame.
However, in case you want to load blank line(s) for doing some explicit calculations like counting empty records, you lot should marking skipping blank lines as False
df_csv = pd.read_csv('csv_example', skip_blank_lines=False, sep=":") That'southward all for this particular mail service
Thank for Reading…!!!
Daksh
Source: https://towardsdatascience.com/pandas-dataframe-playing-with-csv-files-944225d19ff
0 Response to "Read..csv File and Find the Observations and Its Values"
Post a Comment